
The Robotics Breakout Moment
Why now is finally the right time for robotics.
August 7, 2025





We’re entering a new era in robotics. Advances in foundation models and transformer-based AI — along with dramatic improvements in hardware cost and performance — are pushing the field beyond narrow, task-specific automation toward something far more ambitious: generalizable robotic intelligence.
The market is taking notice.
Capital deployed to robotics companies eclipsed $7 billion in 2024, highlighted by mega-rounds in companies like Figure ($675M Series B), Physical Intelligence ($400M Series A), and Skild ($300M Series A).
The global robotics market is forecasted to grow exponentially over the next 5 years as robots achieve general-purpose capabilities and expand from industrial settings into service sectors and consumer homes.
Here’s how that growth breaks down:
- Industrial Robotics: Valued at $34 billion in 2024 and projected to grow by 10% annually over the next decade as automation deepens in manufacturing, warehouse logistics, and construction. It’s worth noting that some analysts believe this market is much larger today and that growth will be even more aggressive, with projections as high as $228B by 2029.
- Service Robotics: Estimated at $42 billion in 2023 and expected to grow by 16% annually through the end of the decade, driven by adoption in healthcare, hospitality, security, and logistics & fulfillment. This is projected to be the fastest growing category in robotics.
- Consumer Robotics: A smaller but rapidly growing segment — ~$14 billion in 2025 — is forecast to grow by 15.5% annually through 2030 as capable, affordable home robots gain traction. A majority of the adoption today is in home cleaning robots, personal companion robots, and robotic toys. By 2030, we anticipate we’ll start seeing humanoids or new form factors used by consumers.
Generalist robotic systems could blur these category lines by enabling robots that can be applied to multiple use cases and verticals, in turn expanding the market even further.
We foresee a thriving robotics ecosystem emerging, and we’re excited to nurture this growth by investing in teams developing robotics foundation models (RFM), full-stack hardware/software solutions, and the broader ecosystem of robotics tooling (e.g., robotics training data providers, simulation platforms).
We dove deep into the robotics market over the last seven months, speaking with dozens of the brightest innovators and experts working in the field today. Through these conversations, we developed a framework for investing in robotics grounded in where the field has been and where it’s heading.
We’ve broken down our analysis into two pieces. In this first article, we’ll explain why now is finally the right time for robotics, focusing on the technologies driving us toward a near future of generalizable robotic intelligence. In a forthcoming second piece, we’ll explain how we’re separating signal from noise in this emerging market and identifying robotics companies that we believe have the potential to change the world.
We’d be remiss not to give credit to content published on robotics that have contributed to our interest and understanding of this space, including thought pieces from Coatue, Colossus, SemiAnalysis, and Salesforce.
Without further adieu, let’s dig in.
Where We’re at Today
Historically, progress in robotics has been slow for a simple reason: it’s an incredibly hard problem to solve. But today we’ve hit an inflection point in our decades-long journey towards general-purpose robotics. We believe the technologies being developed right now will drive broader adoption of robots in industrial manufacturing and logistics, help robotics expand into new sectors like retail, healthcare, and hospitality, and bring robots into consumers’ homes, which we see as the final frontier in the robotics revolution.
While the pace of innovation in generative AI has renewed optimism about robotics breakthroughs, commercializing robots remains a uniquely complex challenge. Success demands excellence across multiple disciplines: hardware design and manufacturing, supply chain logistics, and the development of robust, generalizable robotic foundation models. Robotics teams must make strategic decisions across all of these key disciplines early, and often with high stakes: once a company commits to a certain hardware approach or model architecture, it’s costly and difficult to change course.
So why is this moment different from past waves of robotics enthusiasm? Where earlier efforts were constrained by brittle software and expensive, inflexible hardware, today’s systems are emerging from a vastly improved foundation. In our view, three key areas are driving this shift:
- Scalable data
- Generalizable AI models
- Capable, affordable hardware.
Each area has seen significant recent progress. To understand why the timing is right, let’s explore what’s changed — starting with data, the foundation for building truly intelligent, real-world robots.
1) Data

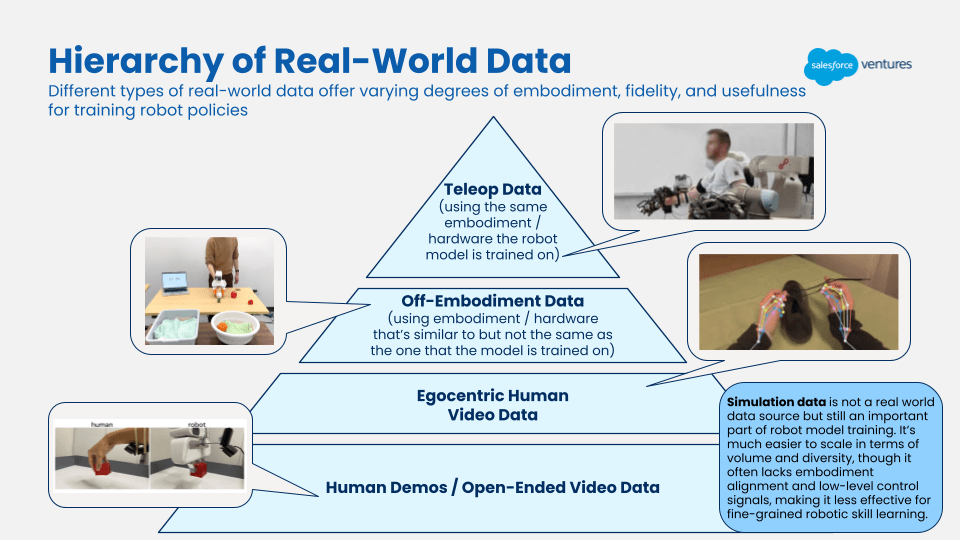
One of the most pressing bottlenecks in robotics today is data. Large language models (LLMs) were trained on vast amounts of readily available internet-scale text data, but there’s no equivalent data source to train robots. Today, robotics researchers and developers rely on a few sources of training data: simulation data, teleoperation data, human video data, and real-world data from deployed robots. These data types vary in terms of ease of access, scalability, and usefulness. Human video data and simulation data are easier to scale and access, but likely only useful in certain aspects of robot learning. Meanwhile, teleoperation data and real-world data from deployed robots are harder to scale and access, but more valuable. The following is a breakdown of how roboticists we’ve spoken to view each source of training data.
Simulation Data
The conventional view in robotics is that simulation data is great at teaching robots how to do locomotion tasks (i.e., moving from one place to another) but harder for teaching manipulation (i.e., the physical interaction of a robot with its environment) because of the sim-to-real gap, where an inherent mismatch between simulated and real environments causes policies learned in simulation to perform sub-optimally in the real world.
This gap is most pronounced in dexterous manipulation because these tasks are inherently more complex. Dexterity requires higher fidelity of visual rendering and is more difficult to simulate due to the nuanced physics of contact, including friction and deformation.
Teleoperation Data
Teleoperation data is data gathered during a human operator’s remote control of robots, and is commonly regarded as the key to unlocking manipulation capabilities. However, it’s hard to scale because it’s resource- and operationally-intensive. Teleoperation data is especially helpful if the human operator is collecting data using the exact kind of hardware the robotics company is using in deployment, so the data collected can be mapped to the robot morphology (physical structure and form of a robot) more precisely. If a similar but inexact kind of hardware is used, the data is considered to be “off-embodiment” — which is still valuable and a good supplement to teleoperation data.
Teleoperation data is resource-intensive because it sometimes requires the manufacturing of custom hardware. Like LLMs, a diversity of data is needed to train robots, meaning a teleoperation project needs different setups, backgrounds, lighting, etc., to achieve data diversity. In a simulation environment, by contrast, all physical factors can be tweaked and simulated.
Human Video Data
Human video data seems like an obvious way to train robots — there’s a massive amount of existing video data on the internet, and it’s easy to create more human video data. Plus, robots are designed morphologically to be similar to humans (i.e., similar physical form). However, not all human video data is created equal for robot training. Ego-centric human video data is the best (i.e., first-person videos recorded from the perspective of the cameraperson). This data resembles what a robot would “see” when equipped with a camera. It also helps with understanding hand-object interactions and human intent.
Further, human video helps with the diversity problem as the human environment has an abundance of diversity (e.g., environments, lighting, obstacles, etc.). However, given human hands and arms are not exactly the same as most robotic arms/manipulators, and these videos often lack action labels, ego-centric human videos are often seen as less valuable than teleoperation data.
_
To summarize the above, the founders of robotics data company xdof.ai shared a great mental model that places the various types of robotic training data into a hierarchy:
Recent Progress in Data Collection
From speaking to many startups training or fine-tuning models with data, we’ve come to realize that robotics is a very diverse and opinionated field → different teams have different views on what will work when it comes to data and are making different bets. This is one of the key differentiators between this wave of robotics innovations and previous trend cycles, when most roboticists relied on similar methods. Additionally, there’s ongoing research in each of the aforementioned data approaches to address shortcomings, leading to continuous breakthroughs around scalability and calling previously held notions into question:
Skild AI has the bold ambition to build a generalizable robotics foundation model. The founders, Deepak Pathak and Abhinav Gupta, share a common vision: “any robot, any task, one brain.” They’re approaching this goal through training a general model, Skild Brain, that utilizes all types of data. Both Deepak and Abhinav have decades of experience in AI and robotics, and are pioneers of several major ideas that have become a standard in robotics today. They published the first major, award-winning paper on sim2real, the first series of papers on learning from videos (e.g., VideoDex, and here), and have been involved in some of the biggest teleoperation data projects (MIME, RT-X). Skild Brain uses simulation and human videos to achieve as many capabilities and as much performance as possible, from locomotion to manipulation, supplemented with teleportation during post-training as needed.
Physical Intelligence, on the other hand, is singularly focused on solving the dexterous manipulation problem in robotics (e.g., being able to manipulate objects in a fine-grained way, such as threading a needle), with the ultimate goal of achieving a fully generalizable model (i.e., across tasks, across hardware). They use a combination of data approaches, and believe there is a spectrum of value of data. Namely, the PI team believes real-world data is irreplaceable for robotic foundation models to generalize effectively, but it’s also important to be pragmatic and use surrogate data (such as simulation data, human video data, etc.) as a supplement, not replacement (much like unrelated but useful pre-training data for LLMs). PI believes this avoids over-engineering correspondences and allows the model to use surrogate sources as broad knowledge rather than precise task instructions. As a result, the team has made a large bet on real-world data and operates a sizable teleoperation lab.
Dyna Robotics is also focused on teleoperation data, but has devised a reinforcement learning (RL) approach to get to product-ready performance with a limited amount of teleoperation data. More on their approach later in the next section.
Companies like the aforementioned xdof.ai have built large-scale teleoperation projects that collect real-world data using specialized and off-the-shelf hardware, recognizing that there’s a massive need for this type of data. Standard Bots is building AI-native, vertically integrated robots and has developed their own proprietary hardware for robot data collection, allowing customers to collect data themselves and teach their robots to do various tasks.
NVIDIA has doubled down on utilizing simulation to scale their data and are supplementing simulation with internet video data, human demonstration data, and teleoperation data. This is the basis of their NVIDIA Isaac Groot foundation model for humanoids. NVIDIA has made their simulation environment available to customers through the NVIDIA Isaac Gym — a high-performance simulation environment designed for RL in robotics. It enables researchers to train complex robotic behaviors efficiently, leveraging GPU acceleration to simulate thousands of environments simultaneously on a single GPU.
Apple’s AI team is also making progress on human video data, having recently released EgoDex in May 2025 — a large scale egocentric video dataset with 3D hand and finger tracking data for teaching robots dexterous manipulation. Apple aims to demonstrate the efficacy of human video data, a passively scalable data source, in training robots.
Tesla recently made use of human video demonstrations to teach their humanoid, Optimus, to do various household tasks — like throwing garbage in a trash can.
_
While it’s still too early to say which method will prove most effective, we believe 1) simulation and human video data will become more important to scaling data pipelines cost-effectively. If general-purpose models are to emerge in the next ~5-10 years (or even sooner), more advanced simulation platforms and more sophisticated approaches to extracting useful information out of human video data will almost certainly be key ingredients. 2) Teleoperation data is also necessary, but there might be ways to reduce the amount needed. We’re seeing creative training approaches that hopefully will achieve good levels of performance with smaller amounts of teleoperation data.
2) Models / Robot Policies
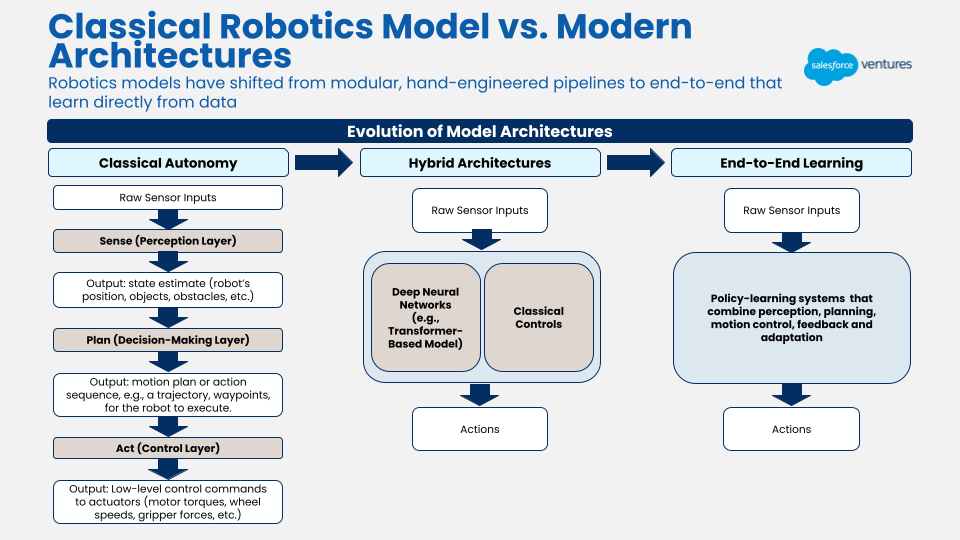
Prior to 2022-2023, the “models” that powered robots were more classical autonomy policies where a modular approach of “sense-plan-act” was applied. Effectively, this means sensory perception, action planning, and motor control were each enabled by a separate system. There are benefits to this approach, including better interpretability (easier to debug) and increased data efficiency. However, these systems didn’t generalize well to new tasks. For each new task, engineers would have to write new rules into the system. As we discussed earlier, the lack of generalizability is one of the reasons that robots haven’t been adopted en masse in the world.
Now comes the promise of transformer models.
The rise of transformer models has driven a shift toward end-to-end architectures, where a single model maps raw sensor inputs (like images, LiDAR, or joint positions) directly to control outputs (motor commands and trajectories), eliminating the need to separate perception, planning, and control into distinct modules. While this is a big step towards generalization, transformer models are also very data hungry (hence the emphasis on data in the previous section). Part of our investment thesis has been focused on companies building these robotics foundation models.
Recent Progress in Robotics Models
Instead of going into a comprehensive timeline of how RFMs have evolved over the last few years, we want to call out some recent breakthroughs at the model layer to showcase what’s currently state-of-the-art. While the rapidly increasing rate of progress means this list will need to be updated soon, it’s helpful to understand where things are at the current moment. Please also note we’re only detailing research that’s publicly available — there are companies we have spoken to that are not disclosing their latest SOTA research to a public audience.
We start with two big tech firms that have been innovating openly in robotics — NVIDIA and Google DeepMind:
NVIDIA’s latest model, Isaac GR00T N1.5, (released in May 2025) is a generalist humanoid robot foundation model — an update to GR00T N1 (released in March 2025) — designed for high-level reasoning and low-level control. It uses a dual-system architecture, which is an approach quite a few RFM developers have taken. System 2 (higher level system) is a vision-language transformer that “thinks slow” about the scene and instructions, and System 1 is a fast diffusion-based flow transformer that outputs continuous joint actions. System 2 processes camera images and language commands into a latent plan; System 1 translates that plan into smooth motor trajectories. GR00T N1.5 is trained end-to-end on a heterogeneous mix of real robot demonstrations, human videos, and vast synthetic datasets (generated via NVIDIA Omniverse). The model takes multimodal input and outputs high-rate continuous action vectors.
The significance of GR00T is that it’s seen as one of the first open, fully customizable humanoid robot models (along with Physical Intelligence’s π₀ model that we will talk about in a bit). Its dual pathway combines general vision-language understanding with a diffusion-policy action generator. GR00T N1.5 improves on N1 with better object recognition and adaptability to new environments via synthetic data. NVIDIA reports that incorporating synthetic motion data (via GR00T-Dreams) boosted task success by ~40% over using only real data.
Google DeepMind’s Gemini Robotics models (first released in March 2025) build on Google’s Gemini 2.0 multimodal foundation to power embodied agents. The family includes two key models:
- Gemini Robotics-ER (Embodied Reasoning): A vision-language model fine-tuned for spatial and temporal understanding. It excels at 3D perception and can even generate robot code for actions (e.g. pick-and-place trajectories). For example, ER can take an image of a cluttered scene and output a grasp point or a language description of the next action.
- Gemini Robotics (Vision-Language-Action): A generalist vision-language-action (VLA) model that adds low-level control on top of ER’s reasoning. It accepts images + language instructions and outputs continuous arm actions to execute tasks. Crucially, this model sets a new state-of-the-art in dexterity: it solves multi-step tasks (origami, card playing, salad-making) with smooth motions and fast completion times. It generalizes to unseen objects and environments via open-vocabulary commands.
Both models are transformer-based and derived from Gemini 2.0, which can interpret images and long text instructions natively, providing a strong base for robotic agents. There are two systems for Gemini Robotics models as well: Gemini Robotics-ER roughly performs the same functionality as System 2 of NVIDIA GR00T (i.e., interpreting the world and reasoning spatially and temporally), and Gemini Robotics VLA is similar to System 1 in that it maps to actions. But this split is not as distinct and strict as is the case with NVIDIA’s models, where System 2 always feeds into System 1.
A few start-ups have also made impressive progress at the model layer:
Skild Brain (released July 2025) is a generalized robotics foundation model developed by Skild AI that can reason/plan across different hardware form factors (e.g., humanoids, quadrupeds, manipulators, etc.). The team calls Skild Brain its “omni-bodied brain.” It utilizes a hierarchical architecture that is similar to NVIDIA and Google, but not quite the same: a low-frequency high-level manipulation and navigation action policy which provides inputs to a high-frequency low-level action policy. In other words, a planning / task layer that provides the commands and an action layer that translates commands into precise joint angles and motor torques to drive the body of the robot.
DYNA-1 (released in April 2025) is a commercial-grade robot policy from startup Dyna Robotics, targeting long-horizon, dexterous tasks (e.g. folding napkins or laundry) with high reliability. Unlike other robot models, DYNA-1 was developed primarily via reinforcement learning (RL) with a novel robotic reward model. The model’s architecture is not fully public, but it consists of deep control policies (on dual-arm hardware) trained end-to-end under extensive real deployment.
DYNA-1 was trained on continuous operation data. A key innovation was Dyna’s custom reward model: it provided fine-grained feedback on task progress for generic long-horizon dexterity tasks (first known task-specific reward model for robotics). This enabled autonomous exploration and error recovery (e.g., the robot learns to detect and fix multi-napkin pulls on its own). Over successive weeks, DYNA-1’s performance steadily improved — from just minutes of stable operation to uninterrupted 24+ hour runs. Dyna Robotics’ goal is to add new tasks to the model over time in an effort to build a generalist model. In contrast to Skild Brain and other models we describe here, it doesn’t aim to be generalist from the get-go.
Physical Intelligence π0.5 (April 2025) is a VLA generalist model, similar in ambition to models like GR00T and Gemini. Its focus is open-world generalization. π0.5 builds on the earlier π₀ model, but co-trains on a heterogeneous mix of data: internet-scale vision-language tasks (QA, captioning, detection) and large-scale multi-robot manipulation demos (various arms, environments). The idea is that by learning from language-rich web data and many robot examples at once, the model can infer the semantics of tasks and then execute them. As π0.5’s designers explain, it learns both “how to pick up a spoon by the handle” (low-level skill) and “where clothes go in a house” (high-level common sense).
π0.5 uses a single transformer for all levels of behavior. At inference, it runs a two-step “chain-of-thought” process: first, the model autoregressively generates a high-level action in text (e.g,. “pick up the pillow”), then repeatedly uses that text to produce continuous joint-action sequences at a higher frequency. Internally, this requires dual components: a VLM backbone for discrete token outputs, and a smaller flow-matching “action expert” for continuous vectors. GR00T has a similar split, but π0.5 shares the VLM backbone between both stages.
Helix (Feb 2025) is also a generalist VLA model from Figure for controlling full humanoid upper bodies. Its main goals are continuous full-body output, multi-robot collaboration, and on-device deployment. Helix also employs a decoupled System-1/2 design. System 2 ingests camera images and the robot’s state (end-effector poses, finger positions) along with a language command, and produces a semantic latent embedding. System 1 is a transformer model with a multi-scale convolutional vision backbone. System 1 takes the same image and state input from System 2, and directly outputs continuous joint actions for both arm, torso, and fingers.
Helix demonstrates full upper-body control. Helix can manipulate the wrist, torso, and fingers simultaneously. It avoids low-dimensional action tokens by directly outputting continuous control in 34 dimensions. It also showcased multi-robot control. The same neural net weights were used to control two robots at once in a collaborative task (putting groceries away). This illustrates that the same policy can control multiple robots simultaneously.
_
Achieving a generalist model is only part of the challenge. To deploy these models in the real world, companies also need a clear hardware strategy — whether that means designing proprietary hardware or leveraging off-the-shelf components from partners. What matters most is that hardware and software are developed in close tandem. The tight feedback loop between physical form factor and AI models is crucial. While custom hardware may not be necessary in every case, it can offer clear advantages when existing form factors don’t support the required tasks.
3) Hardware
Hardware is as important a factor in the advancement of robotics as models and data. In fact, the evolution of hardware alongside robotic software will be crucial to widespread adoption. The following is an overview of recent highlights in hardware innovation that we find interesting and believe are worth mentioning. For a more comprehensive deep-dive into hardware components, SemiAnalysis’ recent post is phenomenal.
Recent breakthroughs in robotic hardware have mainly focused on three different vectors — hardware that is more affordable, more robust, and more agile/dexterous.
- Affordability: To deploy robots en masse, they must be sold at a price that can drive ROI for customers. This means the bill of material (BOM) cost needs to decrease. We’ve seen robots that have BOM costs of $100K+, leading to an even higher sticker price. For the types of tasks these robots typically automate — often labeled “dirty, dangerous, and dull” tasks (e.g., inspecting a chemical plant) — the alternative is hiring human labor that’s hard to source or prone to high turnover. As a result, robot pricing needs to stay below or in line with the cost of equivalent human labor.
- Robustness: A key driver of ROI is a robot’s ability to operate continuously with minimal human intervention — what the robotics world calls “robustness.” For example, a robot that can run 16 or 24 hours straight (covering two or three human shifts) without “bugging out” or needing to recharge delivers clear economic value. Achieving robustness requires both advances in battery life and more durable hardware. But hardware alone isn’t enough: much of robustness depends on the strength of the underlying foundation model powering the system.
- Agility / Dexterity: To be able to perform certain actions or movements, robot arms, hands, torsos, and legs need to have enough degrees of freedom (DOF), which represent the ways in which a robot can move independently. Each degree of freedom typically corresponds to one independent axis of motion. For example, a single DOF for a joint hinge (like an elbow or knee) means it can just go up and down, but two DOF means it can go up/down, as well as left/right, like a wrist. And the model enabling these movements needs to work with the hardware to understand its DOF and how to translate high-level planning into low-level actions. With increasing attention on manipulation skills as we discussed above, dexterous hand designs have become more complex. We also see humanoid designs that can dance, run, do backflips, etc.
Actuators and Sensors
A world where humanoid robots are mainstream requires strong, responsive, and energy-efficient actuators. An actuator is a device that makes a robot move, turning electrical signals into physical motion. Think of them as a robot’s muscles. The development of lighter, more powerful, and compliant actuators is critical to both present and future robotic systems.
Boston Dynamics’ Atlas humanoid robot features fully electric actuators, replacing its older hydraulic system. The electric actuators are compact yet powerful, enabling Atlas to perform a broad range of motions more efficiently and with less complexity. This transition from the more complex, expensive, and leaky hydraulic actuators is representative of the industry’s push towards more sustainable and maintainable systems.
Sensors are effectively the eyes of robotic systems, logging the visual inputs that are fed into the control policy for the robot. Lower-cost, high-resolution RGB-D cameras (which capture both color and depth) have become more commonplace and are foundational to VLM-driven perception systems like RT-2 and DYNA-1.
The evolution of tactile sensors has added the sense of touch to robots, and improved robot dexterity, giving robots the ability to feel pressure, texture, and contact. Amazon’s pick-and-place robot, Vulcan, can now feel objects it grabs, letting it handle up to 75% of warehouse items.
Batteries
Battery life has improved significantly in recent years due to advancements in battery chemistry, better power management, and increased hardware efficiency. Tesla’s Optimus has improved its battery from 2.3 kWh to 3 kWh over the course of 3 designs, which means it can now last up to 8-10 hours per charge in factory settings, lasting for a full human shift. Figure upgraded the battery pack integrated into Figure 02’s torso, so the robot can operate for five hours, a 50% increase in runtime compared to Figure 01.
In a whimsical display of technology, battery and humanoid robot design were recently stress tested in the humanoid robot half-marathon race in Beijing: only 6 out of the 21 robots completed the race due to battery failures, overheating, etc. However, Tiangong Ultra completed the race in 2 hours and 40 minutes with only 3 battery swaps — an impressive feat for a robot running such a distance and a massive improvement over the 8 hours it took the same robot to complete the race one year earlier.
Teleoperation Hardware
Earlier we talked about the importance of teleoperation in terms of data collection and model training. Advanced teleoperation interfaces have made it easier for humans to control robots with precision and minimal lag. Commodity VR headsets and inexpensive setups like GELLO have made teleoperation more accessible, but hardware innovation continues to push the field forward. Cutting-edge teleoperation hardware features haptic feedback systems, which give operators a sense of touch, improving accuracy and reducing errors. DOGlove, which debuted at ICRA this year, is an open-source, low-cost haptic glove designed for dexterous telemanipulation. HOMIE is an exoskeleton teleoperation hardware that combines arms, gloves, and foot pedals for loco-manipulation teleoperation.
Hand Technology
ICRA declared 2025 as the year for robotic hands. Several research groups showcased hands capable of in-hand manipulation, demonstrating tasks like spinning a pen in your hand or dealing out a deck of cards. Most notably, Sharpa Robotics demoed their robotic hand at the conference, which features 22 degrees of freedom and advanced tactile sensing. While standard parallel grippers can perform a substantial portion of manipulation tasks, many believe more advanced human-like robot hands are required for highly dexterous tasks. However, this is still an open research question.
For context, 22 degrees of freedom is close to the human hand, which has 27 degrees of freedom. The only robotic hand we’ve heard of that has that level of dexterity is Clone Robotics, which also boasts of a robotic hand that’s “the most biomimetic hand” made of synthetic materials that feel like soft muscle. A few other robotics companies, such as Tesla Optimus and Shadow Robot, are also working on hands with increasing levels of dexterity.
Humanoids
Humanoids as a form factor of robotic systems have been gaining in popularity in recent years. The argument being the world is designed for humans, so to have generalizable robotic systems that do what humans do, we need a form factor that’s similar in morphology. It’s a complex undertaking but we’ve seen some promising progress.
Figure is building a highly customized humanoid form factor and is building everything in-house down to the actuators, sensors, batteries, and electronics — which they’re manufacturing and assembling in their BotQ facility. Figure 02, unveiled in August 2024, has redesigned hands that offer 16 DOF, closely mimicking human hand movements, and can lift objects up to 25 kg (55 lbs). And yes, Figure AI is actively developing its third-generation humanoid robot, Figure 03.
Tesla Optimus is also building a highly customized humanoid with a fully verticalized supply chain (as it has done for Tesla cars). The latest iteration, Optimus Gen-3, features significant refinements such as a highly articulated 22 DOF hand, enabling nuanced manipulation and tasks like catching objects mid-air. To enhance agility and balance, Tesla redesigned joint geometry, especially in the ankles and arms, supporting more natural and fluid movements. Moreover, Optimus has adopted novel drive mechanisms like tendon-driven ball-screw transmissions that convert rotational motion into linear motion with efficiency and minimal friction. Integration with xAI’s Grok conversational AI further amplifies its capabilities, allowing seamless human-like interactions.
Unitree’s ongoing hardware innovations are helping make advanced robotics far more accessible. Their G1 humanoid, for example, starts at just $16k. Both their humanoid and quadruped platforms come equipped with cutting-edge depth-sensing and perception systems. The G1 includes built-in AI for balance, vision, and object detection, and is primarily used by hobbyists and researchers. In contrast, Unitree’s flagship H1 robot model is a more powerful humanoid design and features significantly higher compute power and degrees of freedom, making it well-suited for advanced R&D and foundation model fine-tuning.
This is by no means a comprehensive list given the nuances and complexity here. The other companies developing humanoid robotics that are worth mentioning are 1X and Clone Robotics, both of which have designed a sleek humanoid form factor with soft exoskeleton.
Lessons From Past Robotics Cycles
Besides technological advancements, today’s robotics companies are learning from the misfires and false starts of previous robotics innovation cycles. It’s fair to acknowledge that historically, robotics companies have failed to meet commercial expectations despite high volumes of venture funding. As we look toward this new era of robotics, it’s important to reflect on the lessons from previous cycles — what didn’t work and what’s different now.
The Unfulfilled Promise of Autonomous Vehicles (AVs)
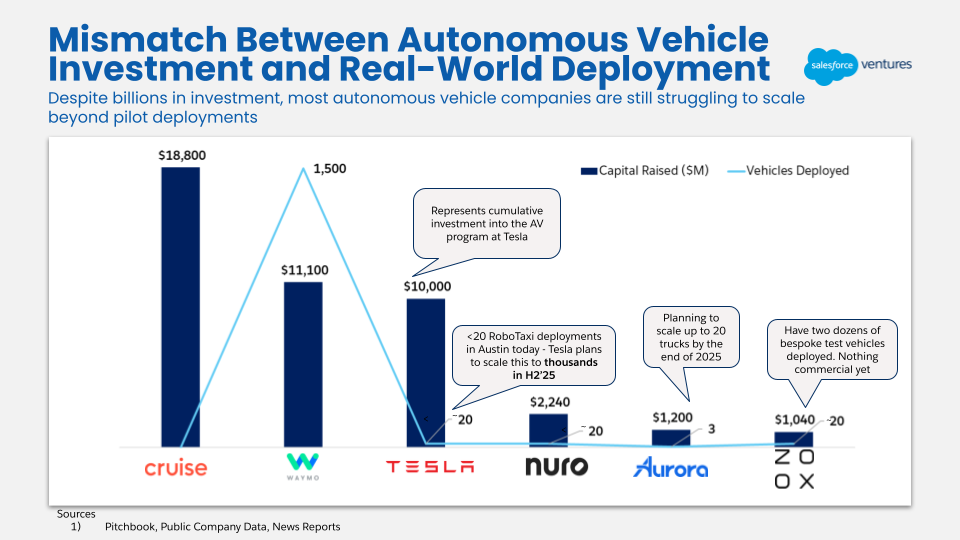
The AV hype cycle peaked from 2015-2020, with billions of venture dollars poured into companies like Cruise and Zoox. The market expected fully self-driving cars at scale years ago, and while Waymos are ubiquitous in certain cities (and provide a delightful experience), they’ve only achieved Level 4 autonomy (meaning no driver is required, but their usage is limited to specific areas). Similarly, Tesla’s FSD still requires a driver to stay fully attentive at all times.
One of the key challenges AVs face is that long-tail edge cases are extremely difficult to solve for. Given that autonomous vehicles operate in the open world, there’s a very long tail of edge cases that are challenging to address, such as pedestrians behaving unpredictably or erratic driving behavior. AVs often fail due to encountering scenarios that are OOD, or “out of distribution.” Many companies, including Cruise, have tried to solve this issue simply by collecting more and more data until these edge cases are solved for. This is a major reason it has taken so much longer to realize AVs than expected — it takes a long time to acquire enough data to account for the long tail of edge cases AVs need to meet safety and performance guarantees. While many robots may be deployed in much more structured environments compared to autonomous vehicles, teams tackling consumer environments may encounter similar issues to the AV industry.

Another challenge plaguing the AV industry is the track record of these companies overpromising and underdelivering. Tesla, Waymo, and Uber, among others, have repeatedly raised expectations on when we’d achieve Level 4 autonomy, and yet it’s taken longer than expected. Flashy demos were not representative of actual, real-world deployments, eroding public trust and enthusiasm for AVs. This is why many robotics founders are, or should be, cautious when setting expectations with the public.
Fast & Scalable Deployments Matter
Having a functional robot isn’t enough; companies need to develop a repeatable and scalable deployment motion to move beyond the pilot phase. Many robotics companies from the 2014-2015 era made the mistake of getting stuck performing one-off integrations for each customer, leaving them without a clear path to broader implementation and scale. We talked to a couple of companies from this previous wave of innovation, and the biggest mistake operators pointed to was spending more time doing engineering work on the implementation than building the AI model and the robot. While challenging, robots should be designed to adapt to various environments with minimal reconfiguration. Teams must also possess the resources to ensure successful deployment, whether through in-house capabilities or partnerships with system integrators.
A robot’s adaptability and ease of deployment often hinge on how generalizable both the robot and its underlying model are. It’s possible that the previous generation of robotics companies didn’t have models or robot policies that could be generalized in different settings / customer environments, leading to long and arduous implementation work. With a robust robotics foundation model that’s truly generalizable, this could cease to be a problem.
Timing is Everything
Many robotics companies from previous waves were simply too early. They lacked the hardware efficiency, scalable data collection methods, and AI capabilities available today. The convergence of progress in these key areas mean a lot of what didn’t work back then is technically feasible now.
The Case for Robotics, Now
While we’re still a ways off from truly mainstream robotics, the rate of progress across robotic training data, robot models, and robotic hardware is accelerating meaningfully. If current trends continue, it’s likely that we’ll see general-purpose robots deployed in the open world faster than we saw autonomous vehicles reach scale.
In short, robots are coming. Fast. We’re excited to nurture this growth across RFMs, full-stack hardware/software solutions, and the broader ecosystem of robotics tooling (e.g., data providers, simulation platforms). In our next article, we’ll dive deep into our robotics investment approach in an effort to offer a framework to fellow investors interested in the space.
_
We’ve spent the past seven months embedded in the world of robotics, and we’ve still only scratched the surface. Robotics is by far one of the hardest technical disciplines we’ve ever encountered. We’d love to hear your feedback on our views above. And if you’re building in robotics today, we’d love to connect and learn more about your business. Email Emily Zhao at emily@salesforceventures.com and Pascha Hao at pascha@salesforceventures.com.
This article is part of our series on robotics. Additional resources can be found here:





